


一万亿晶体管GPU将到来,台积电董事长撰文解读
【蜂耘网 IT业界】在之前的演讲介绍中,台积电曾多次谈到了万亿晶体管的路线图。今天,在IEEE网站上,发表了一篇署名为《How We’ll Reach a 1 Trillion Transistor GPU》的文章,讲述了台积电是如何达成万亿晶体管芯片的目标。
值得一提的是,本文署名作者MARK LIU(刘德音)和H.-S. PHILIP WONG,其中刘德音是台积电董事长。H.-S Philip Wong则是斯坦福大学工程学院教授、台积电首席科学家。
在这里,我们将此文翻译出来,以飨读者。

以下为文章正文:
1997 年,IBM 深蓝超级计算机击败了国际象棋世界冠军Garry Kasparov。这是超级计算机技术的突破性演示,也是对高性能计算有一天可能超越人类智能水平的首次展示。在接下来的10年里,我们开始将人工智能用于许多实际任务,例如面部识别、语言翻译以及推荐电影和商品。
再过十五年,人工智能已经发展到可以“合成知识”(synthesize knowledge)的地步。生成式人工智能,如ChatGPT和Stable Diffusion,可以创作诗歌、创作艺术品、诊断疾病、编写总结报告和计算机代码,甚至可以设计与人类制造的集成电路相媲美的集成电路。
人工智能成为所有人类事业的数字助手,面临着巨大的机遇。ChatGPT是人工智能如何使高性能计算的使用民主化、为社会中的每个人带来好处的一个很好的例子。
所有这些奇妙的人工智能应用都归功于三个因素:高效机器学习算法的创新、训练神经网络的大量数据的可用性,以及通过半导体技术的进步实现节能计算的进步。尽管它无处不在,但对生成式人工智能革命的最后贡献却没有得到应有的认可。
在过去的三十年里,人工智能的重大里程碑都是由当时领先的半导体技术实现的,没有它就不可能实现。Deep Blue 采用 0.6 微米和 0.35 微米节点芯片制造技术的混合实现;赢得 ImageNet 竞赛的深度神经网络并开启了当前机器学习时代的设备使了用 40 纳米技术打造的芯片;AlphaGo 使用 28 纳米技术征服了围棋游戏;ChatGPT 的初始版本是在采用 5 纳米技术构建的计算机上进行训练的。;ChatGPT 的最新版本由使用更先进的4 纳米技术的服务器提供支持。所涉及的计算机系统的每一层,从软件和算法到架构、电路设计和设备技术,都充当人工智能性能的乘数。但可以公平地说,基础晶体管器件技术推动了上面各层的进步。
如果人工智能革命要以目前的速度继续下去,它将需要半导体行业做出更多贡献。十年内,它将需要一个 1 万亿晶体管的 GPU,也就是说,GPU 的设备数量是当今典型设备数量的 10 倍。
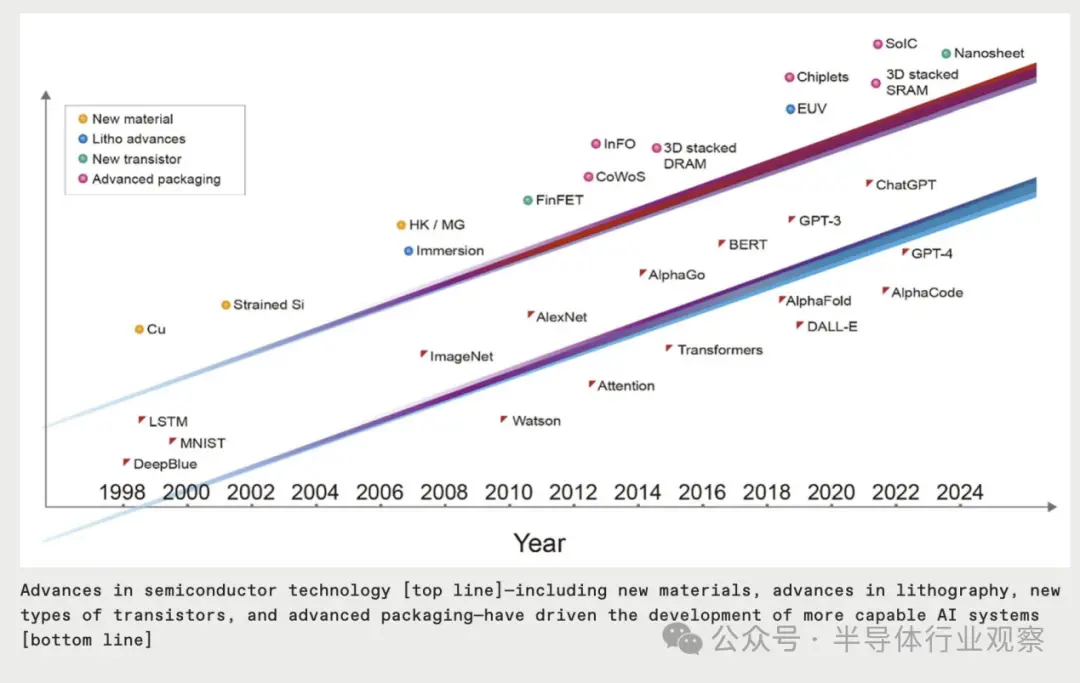
AI 模型大小的不断增长,让人工智能训练所需的计算和内存访问在过去五年中增加了几个数量级。例如,训练GPT-3需要相当于一整天每秒超过 50 亿次的计算操作(即 5,000 petaflops /天),以及 3 万亿字节 (3 TB) 的内存容量。
新的生成式人工智能应用程序所需的计算能力和内存访问都在持续快速增长。我们现在需要回答一个紧迫的问题:半导体技术如何跟上步伐?
从集成器件到集成小芯片
自集成电路发明以来,半导体技术一直致力于缩小特征尺寸,以便我们可以将更多晶体管塞进缩略图大小的芯片中。如今,集成度已经上升了一个层次;我们正在超越 2D 缩放进入3D 系统集成。我们现在正在将许多芯片组合成一个紧密集成、大规模互连的系统。这是半导体技术集成的范式转变。
在人工智能时代,系统的能力与系统中集成的晶体管数量成正比。主要限制之一是光刻芯片制造工具被设计用于制造不超过约 800 平方毫米的 IC,即所谓的光罩限制(reticle limit)。但我们现在可以将集成系统的尺寸扩展到光刻掩模版极限之外。通过将多个芯片连接到更大的中介层(一块内置互连的硅片)上,我们可以集成一个系统,该系统包含的设备数量比单个芯片上可能包含的设备数量要多得多。例如,台积电的CoWoS(chip-on-wafer-on-substrate )技术就可以容纳多达六个掩模版区域的计算芯片,以及十几个高带宽内存(HBM)芯片。
CoWoS是台积电的硅晶圆上芯片先进封装技术,目前已在产品中得到应用。示例包括 Nvidia Ampere 和 Hopper GPU。当中每一个都由一个 GPU 芯片和六个高带宽内存立方体组成,全部位于硅中介层上。计算 GPU 芯片的尺寸大约是芯片制造工具当前允许的尺寸。Ampere有540亿个晶体管,Hopper有800亿个。从 7 纳米技术到更密集的 4 纳米技术的转变使得在基本相同的面积上封装的晶体管数量增加了 50%。Ampere 和 Hopper 是当今大型语言模型 ( LLM ) 训练的主力。训练 ChatGPT 需要数万个这样的处理器。
HBM 是对 AI 日益重要的另一项关键半导体技术的一个例子:通过将芯片堆叠在一起来集成系统的能力,我们在台积电称之为SoIC (system-on-integrated-chips) 。HBM 由控制逻辑 IC顶部的一堆垂直互连的 DRAM 芯片组成。它使用称为硅通孔 (TSV) 的垂直互连来让信号通过每个芯片和焊料凸点以形成存储芯片之间的连接。如今,高性能 GPU广泛使用 HBM 。
展望未来,3D SoIC 技术可以为当今的传统 HBM 技术提供“无凸块替代方案”(bumpless alternative),在堆叠芯片之间提供更密集的垂直互连。最近的进展表明,HBM 测试结构采用混合键合技术堆叠了 12 层芯片,这种铜对铜连接的密度高于焊料凸块所能提供的密度。该存储系统在低温下粘合在较大的基础逻辑芯片之上,总厚度仅为 600 µm。
对于由大量运行大型人工智能模型的芯片组成的高性能计算系统,高速有线通信可能会很快限制计算速度。如今,光学互连已被用于连接数据中心的服务器机架。我们很快就会需要基于硅光子学的光学接口,并与 GPU 和 CPU 封装在一起。这将允许扩大能源效率和面积效率的带宽,以实现直接的光学 GPU 到 GPU 通信,这样数百台服务器就可以充当具有统一内存的单个巨型 GPU。
由于人工智能应用的需求,硅光子将成为半导体行业最重要的使能技术之一。
迈向万亿晶体管 GPU
如前所述,用于 AI 训练的典型 GPU 芯片已经达到了标线区域极限(reticle field limit)。他们的晶体管数量约为1000亿个。晶体管数量增加趋势的持续将需要多个芯片通过 2.5D 或 3D 集成互连来执行计算。通过 CoWoS 或 SoIC 以及相关的先进封装技术集成多个芯片,可以使每个系统的晶体管总数比压缩到单个芯片中的晶体管总数大得多。如AMD MI 300A 就是采用这样的技术制造的。
AMD MI300A 加速处理器单元不仅利用了CoWoS,还利用了台积电的 3D 技术SoIC。MI300A结合了 GPU 和 CPU内核,旨在处理最大的人工智能工作负载。GPU为AI执行密集的矩阵乘法运算,而CPU控制整个系统的运算,高带宽存储器(HBM)统一为两者服务。采用 5 纳米技术构建的 9 个计算芯片堆叠在 4 个 6 纳米技术基础芯片之上,这些芯片专用于缓存和 I/O 流量。基础芯片和 HBM 位于硅中介层之上。处理器的计算部分由 1500 亿个晶体管组成。
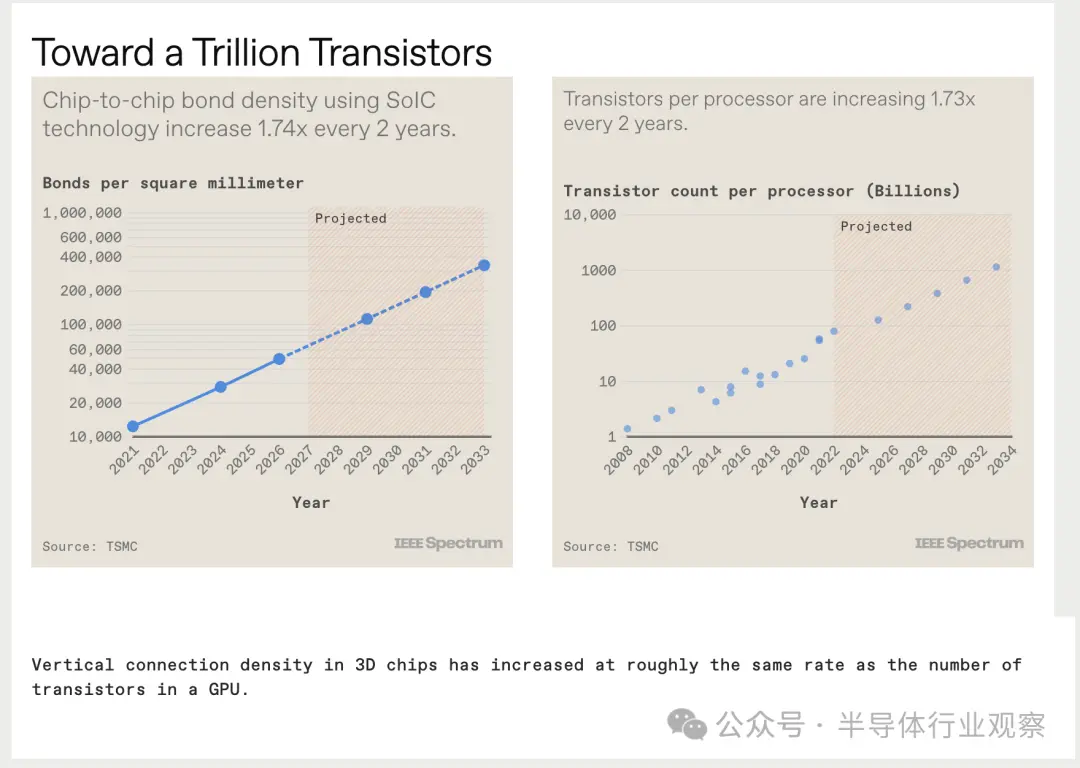
我们预测,十年内,多芯片 GPU 将拥有超过 1 万亿个晶体管。
我们需要在 3D 堆栈中将所有这些小芯片连接在一起,但幸运的是,业界已经能够快速缩小垂直互连的间距,从而增加连接密度。而且还有足够的空间容纳更多。我们认为互连密度没有理由不能增长一个数量级,甚至更高。
GPU 的节能性能趋势
那么,所有这些创新的硬件技术如何提高系统的性能呢?
如果我们观察一个称为节能性能的指标的稳步改进,我们就可以看到服务器 GPU 中已经存在的趋势。EEP 是系统能源效率和速度(the energy efficiency and speed of a system)的综合衡量标准。过去 15 年来,半导体行业的能效性能每两年就提高了三倍左右。我们相信这一趋势将以历史速度持续下去。它将受到多方面创新的推动,包括新材料、器件和集成技术、极紫外(EUV)光刻、电路设计、系统架构设计以及所有这些技术元素的共同优化等。
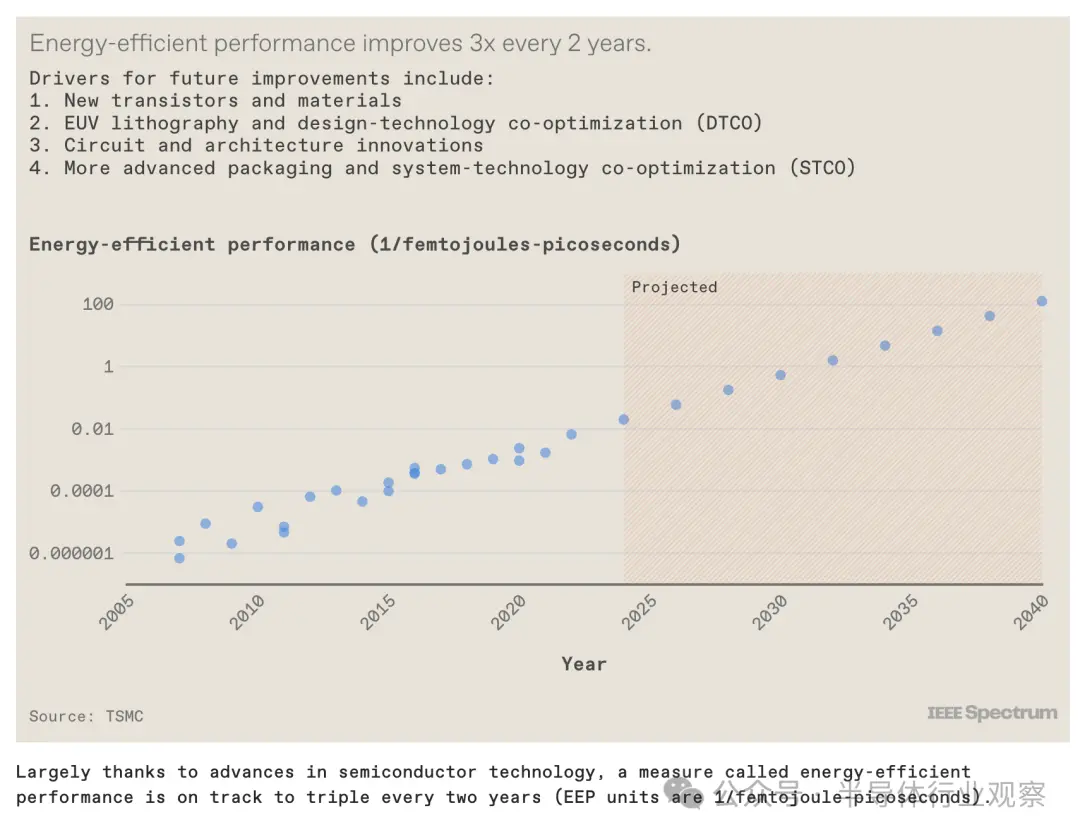
特别是,EEP 的增加将通过我们在此讨论的先进封装技术来实现。此外,系统技术协同优化 (STCO:system-technology co-optimization)等概念将变得越来越重要,其中 GPU 的不同功能部分被分离到各自的小芯片上,并使用性能最佳和最经济的技术来构建每个部分。
3D 集成电路的Mead-Conway时刻
1978年,加州理工学院教授Carver Mead和施乐帕洛阿尔托研究中心的Lynn Conway发明了集成电路的计算机辅助设计方法。他们使用一组设计规则来描述芯片缩放,以便工程师可以轻松设计超大规模集成(VLSI)电路,而无需了解太多工艺技术。
3D 芯片设计也需要同样的功能。如今,设计人员需要了解芯片设计、系统架构设计以及硬件和软件优化。制造商需要了解芯片技术、3D IC技术和先进封装技术。正如我们在 1978 年所做的那样,我们再次需要一种通用语言,以电子设计工具可以理解的方式描述这些技术。这种硬件描述语言使设计人员可以自由地进行 3D IC 系统设计,而无需考虑底层技术。它正在路上:一种名为3Dblox 的开源标准已被当今大多数技术公司和电子设计自动化 (EDA) 公司所接受。
隧道之外的未来
在人工智能时代,半导体技术是人工智能新能力和应用的关键推动者。新的 GPU 不再受过去的标准尺寸和外形尺寸的限制。新的半导体技术不再局限于在二维平面上缩小下一代晶体管。集成人工智能系统可以由尽可能多的节能晶体管、用于专门计算工作负载的高效系统架构以及软件和硬件之间的优化关系组成。
过去 50 年来,半导体技术的发展就像走在隧道里一样。前面的路很清晰,因为有一条明确的道路。每个人都知道需要做什么:缩小晶体管。
现在,我们已经到达隧道的尽头。从这里开始,半导体技术将变得更加难以发展。然而,在隧道之外,还有更多的可能性。我们不再受过去的束缚。
(蜂耘IT业界网 责任编辑:辛渺)
在之前的演讲介绍中,台积电曾多次谈到了万亿晶体管的路线图。今天,在IEEE网站上,发表了一篇署名为《How We’ll Reach a 1 Trillion Transistor GPU》的文章,讲述了台积电是如何达成万亿晶体管芯片的目标。
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
-

第四届武汉应博会4月24日开幕 应急救援特种车辆将现场亮相
来源: 工人日报
日前,第四届武汉国际安全应急博览会(以下简称武汉应博会)组委会透露,2024年第四届武汉应博会将于4月24日至26日在武汉国际博览中心举行,百余款“高精尖”的应急救援装备和新产品新技术将亮相。2024-04-23
-

深厦物联网企业家交流对接会成功举办
来源:深圳市物联网产业协会
4月19日上午,由深圳市物联网产业协会、厦门市物联网行业协会联合主办,厦门星纵物联科技有限公司承办,深圳市讯鹏科技有限公司、深圳市铨顺宏科技有限公司协办的“深厦物联网企业家交流对接会”在星纵总部大楼圆满举办,会议吸引了30多位物联网领域的企业家和行业精英共聚一堂。2024-04-23


- 2022-08-25
- 2022-10-24
- 2022-10-13
- 2022-09-30
- 2023-03-29
- 2022-10-18
- 2022-11-17
- 2022-10-25
-

一文了解查理·芒格:为什么他是巴菲特最推崇的人
来源:
①巴菲特写道,“如果没有查理的灵感、智慧和参与,伯克希尔-哈撒韦公司不可能发展到今天的地位”;
②芒格曾表示,“如果世上未曾有过查理·芒格这个人,巴菲特的业绩依然会像现在这么漂亮 ”
③两周前,芒格还公开在节目中维护93岁的老友巴菲特。넶30 2023-11-29 -

面壁者,拉里·佩奇
来源:中欧商业评论
这两年,硅谷钢铁侠埃隆·马斯克在社交媒体上口无遮拦,这为他的公司引来了铺天盖地的负面新闻,然而,他的好友、谷歌联合创始人拉里·佩奇却因为看不到人同样被媒体炮轰多时。他已经在公共视野中消失太久了。넶137 2022-06-15 -

百岁中科院院士文圣常逝世!被誉为我国海浪研究的“点灯人”
来源:南方都市报
3月21日上午,中国海洋大学发布讣告,中国科学院院士、著名物理海洋学家、该校教授文圣常,因病医治无效,于3月20日15时37分在山东青岛逝世,享年101岁。넶164 2022-03-21



-

2023人工智能产业生态峰会(深圳站)即将举行!
来源:蜂耘网
本届大会以“产业变革 · 抓住机遇”为主题,聚焦国内人工智能的最新技术理念与解决方案,邀请众多行业大咖、专家学者分享最新的研究成果、技术、解决方案、行业报告、未来发展趋势等。넶153 2023-07-04 -

物流“黑科技”全力竞发 中国(广州)国际物流装备与技术展览会5月强势来袭!
来源:蜂耘网
立足华南联通世界,物流“黑科技”全力竞发!中国(广州)国际物流装备与技术展览会5月强势来袭!넶79 2023-05-05 -




- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23
- 2024-04-23

